我说分布式之Gossip协议与Raft算法概览
如果说分布式领域是一片蓝海,那各种分布式一致性算法就是其中闪耀的明珠。
本文中,我将着重介绍两个有趣且应用广泛的分布式一致性算法,Gossip协议与Raft算法。
Gossip协议
首先介绍一下Gossip协议,它的通俗解释如下:
Gossip protocol 也叫 Epidemic Protocol (流行病协议),它还有很多别名,如:“谣言算法”、“疫情传播算法”等。
这个协议的作用就像其名字表示的意思一样容易理解,它的运行方式在我们日常生活中也很常见,如疾病致病病菌的传播,森林大火扩散等。
Gossip协议的思想比较有趣,它的集群拓扑是去中心化的,如下图所示,是一个抽象的Gossip集群拓扑。
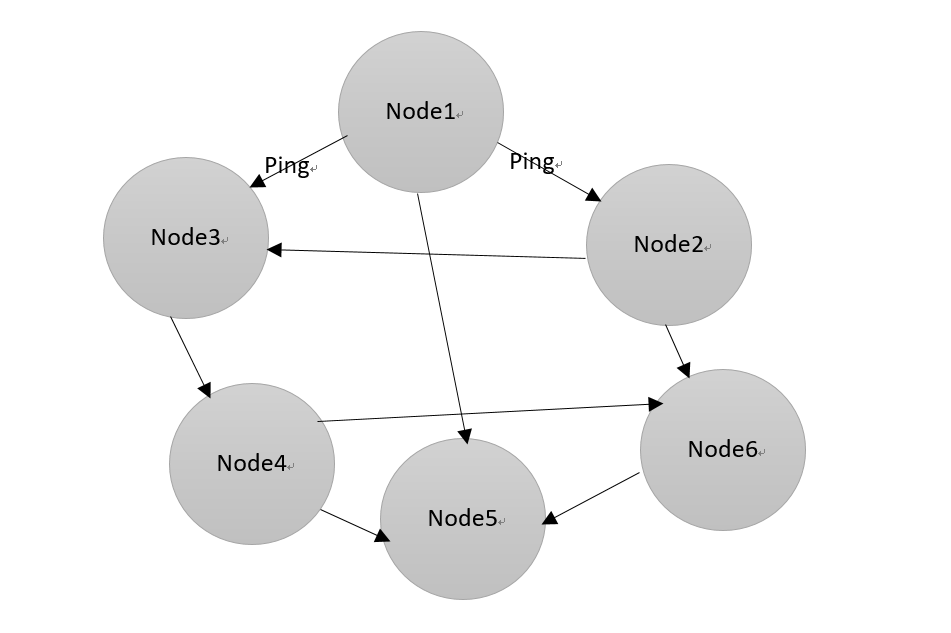
图中的每个节点均为运行着Gossip协议的Agent,包括服务器节点与普通节点,他们均加入了此Gossip集群并收发Gossip消息。
每经过一段固定的时间,每个节点都会随机选取几个与它保持连接的若干节点发送Gossip消息,与此同时,其他节点也会选择与自己保持连接的几个节点进行消息的传递。如此经过一点时间之后,整个集群都收到了这条Gossip消息,从而达到最终一致。
注意 每次消息传递都会选择 尚未发送过的节点 进行散播,即收到消息的节点不会再往发送的节点散播,eg:A->B, 则当B进行散播的时候,不会再发送给A。
这样做的好处是当集群中的节点总量增加,分摊到每个节点的压力基本是稳定的,在一致性时间窗的忍耐限度内,整个集群的规模可以达到数千节点。
Gossip已经落地的产品包括但不限于Consul、Cassandra。其中Consul主要使用Gossip做为集群成员管理及消息广播的主要手段。Consul的Agent之间通过Gossip协议进行状态检查,通过节点之间互ping而减轻了作为server的节点的压力。如果有节点down机,任意与其保持连接的节点发现即可通过Gossip广播给整个集群。当该down机的节点重启后重新加入集群,一段时间后,它的状态也能够通过Gossip协议与其他的节点达成一致,这体现出Gossip协议具有的天然的分布式容错的特点。
Gossip算法又被称为反熵(Anti-Entropy),表示在杂乱无章中寻求一致,这充分说明了Gossip的特点:在一个有界网络中,每个节点都随机地与其他节点通信,经过一番杂乱无章的通信,最终所有节点的状态都会达成一致。每个节点可能知道所有其他节点,也可能仅知道几个邻居节点,只要这些节可以通过网络连通,最终他们的状态都是一致的,当然这也是疫情传播的特点。
Raft算法
接着了解下Raft算法,度娘如此介绍:
Raft是一种共识算法,旨在替代Paxos。 它通过逻辑分离比Paxos更容易理解,但它也被正式证明是安全的,并提供了一些额外的功能。[1] Raft提供了一种在计算系统集群中分布状态机的通用方法,确保集群中的每个节点都同意一系列相同的状态转换。
Raft通过当选的领导者达成共识。筏集群中的服务器是领导者或追随者,并且在选举的精确情况下可以是候选者(领导者不可用)。领导者负责将日志复制到关注者。它通过发送心跳消息定期通知追随者它的存在。每个跟随者都有一个超时(通常在150到300毫秒之间),它期望领导者的心跳。接收心跳时重置超时。如果没有收到心跳,则关注者将其状态更改为候选人并开始领导选举。
Raft算法的主要包含如下要点:
- leader选取
- 日志复制
- 安全
我们主要介绍leader选举以及日志复制,安全相关的内容本文不做展开讲解。
Raft流程
首先,需要明确一个概念:
raft 集群中的每个节点都可以根据集群运行的情况在三种状态间切换:follower(从节点), candidate(候选者节点) 与 leader(主节点)。
它们的职责描述如下:
leader节点
leader节点向follower节点进行日志同步
follower节点
follower节点只能从leader节点获取日志。
我们将通过一系列的拓扑图介绍下Raft协议是如何运行的。
Raft基本流程
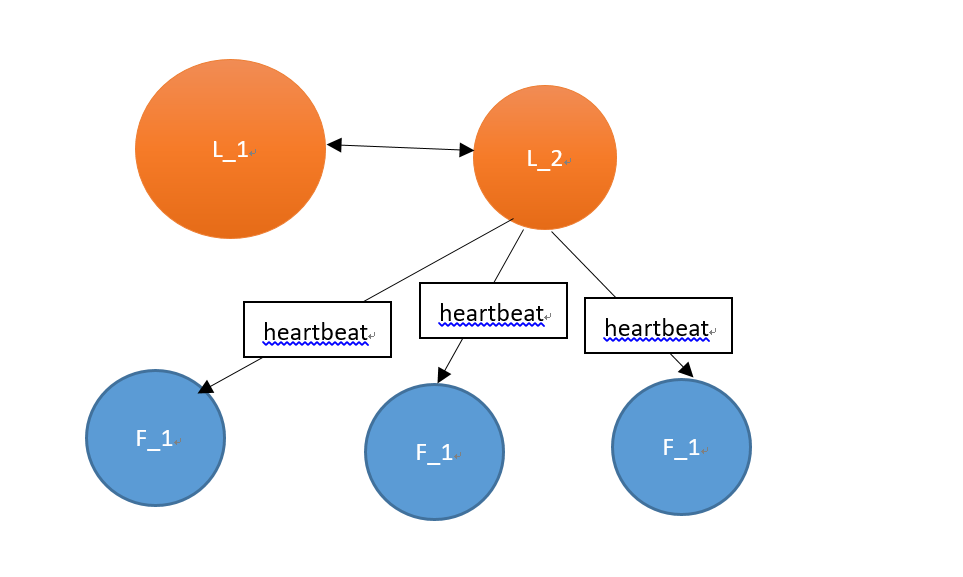
正常情况下,leader节点定时向follower节点发送heartbeat心跳包。
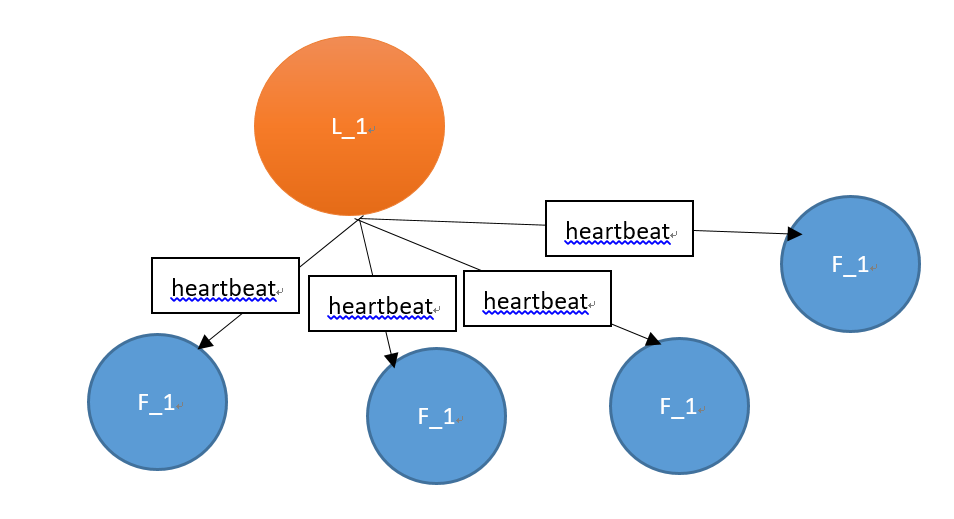
由于某些异常情况发生,leader不再发送心跳包,或者因为网络超时,导致follower无法收到心跳包。如下
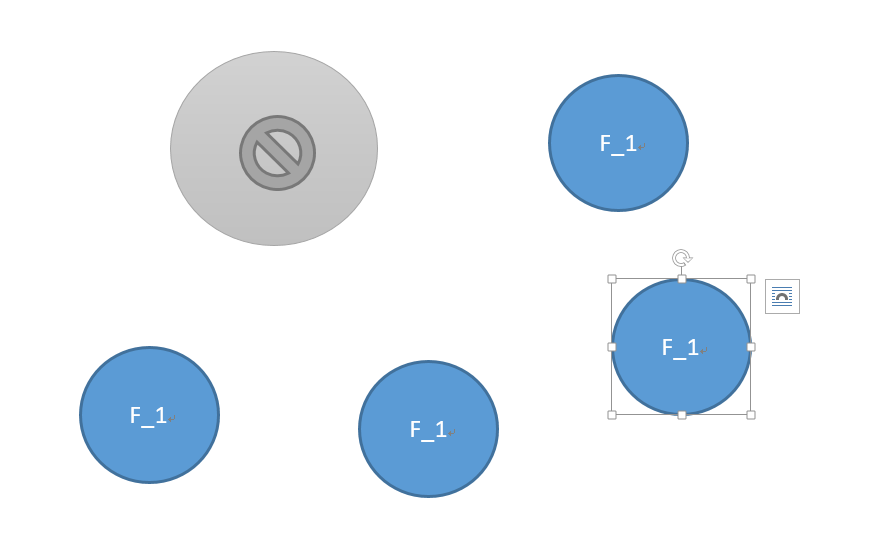
此时,如果在一个时间周期(election timeout),follower没有收到来自leader的心跳包,则节点将会发起leader选举。
某个节点发生election timeout,节点的 raft 状态机将自己的状态变更为candidate(候选者),并向其余的follower发起投票。
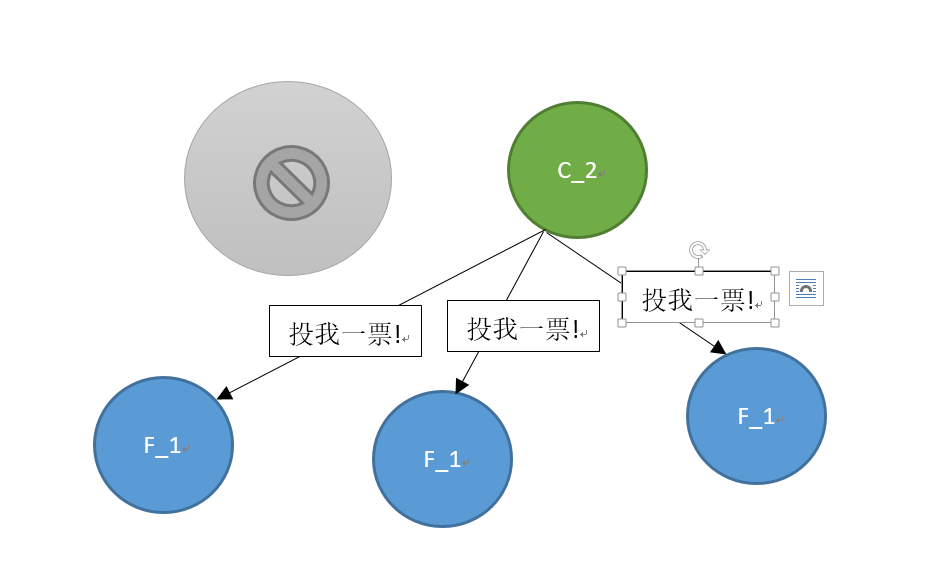
当该候选节点收到了集群中超过半数的节点的接受投票响应后,该候选节点成为leader节点,并开始接受并保存client的数据对外提供服务,并向其余的follower节点同步日志。它作为leader节点同时还会向其余的存活的follower节点发送heartbeat心跳包来保持其leader地位。
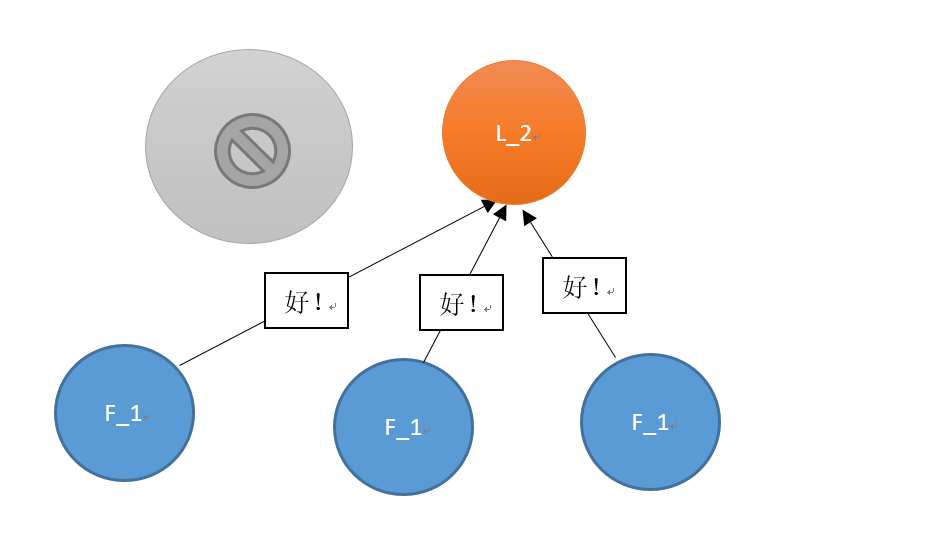
当经过一点时间后,原先的leader重启并重新加入到集群中,此时需要比较两个leader的步进数,步进数低的那个leader将切换为follower节点(此处即为重启恢复的那个leader)
:
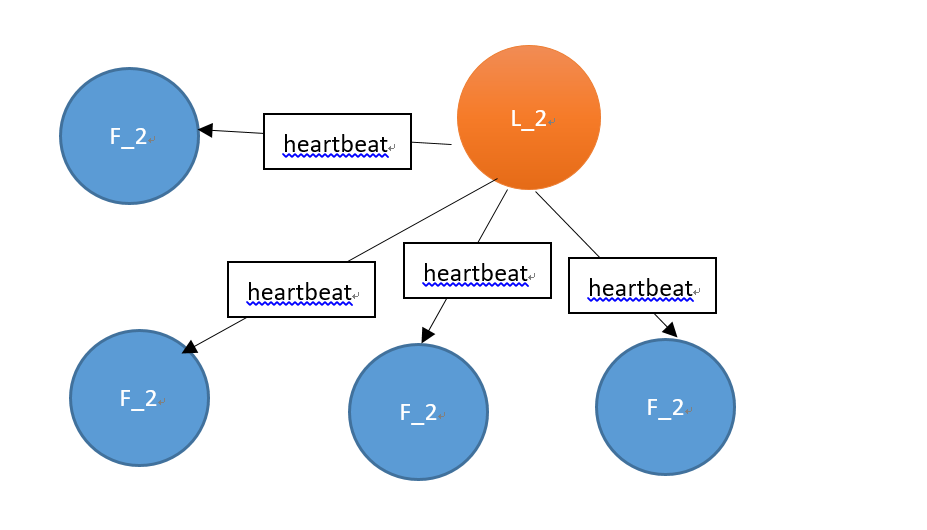
此时leader节点已经变更,因此之前的那个leader节点(此时已经是follower)中的日志将会被清理,并作为follower接受当前leader的日志同步,从而保持一致。
小结复盘
关于Gossip协议,我们需要了解最终一致的达成过程,同时我们需要知道当前已落地的应用为Cassandra缓存中间件、Consul等。
关于Raft,我们要明确两个要素: 选主以及日志复制,目前落地Raft协议的中间件有:Etcd、consul等。
参考链接
Consul实现原理系列文章2: 用Gossip来做集群成员管理和消息广播
版权声明:
原创不易,洗文可耻。除非注明,本博文章均为原创,转载请以链接形式标明本文地址。
