研磨消息中间件kafka之高吞吐低延时策略
提升Kafka对消息处理的吞吐量及低延时主要通过磁盘顺序写、零拷贝(zero copy)以及利用页缓存(Page Cache)实现。下面我们进行具体说明。
消息顺序写
Kafka的消息存储在每次写入时,只是将数据写入到操作系统的页缓存(PageCache)中,最终是由操作系统决定何时将页缓存中的数据落盘的。这样做的好处如下:
- 由于页缓存是OS在内存中分配的,因此消息写入速度很快;
- 由于Kafka将消息写入页缓存中,因此避免了直接与底层文件系统打交道时候的繁琐流程,所有的I/O操作均交给了操作系统进行处理;
- Kafka写操作采用了append方式(即:追加写入),这种顺序写盘的方式速度很快,避免了因随机写而导致的写入效率低下。
对于上述的第三点,着重进行解析:
对于机械硬盘而言,对数据进行随机读写的吞吐量往往是很低的,但如果读写是顺序的,则速度很快,其顺序读写的速度甚至接近内存的随机I/O。而Kafka正是因此而采用了append方式进行消息的写入。
即:只在日志文件的末尾追加写入新消息,同时对于已经写入的消息,不允许进行修改。
正因为Kafka采用的是磁盘顺序访问方式,所以其消息发送的吞吐量很高,实际使用中达到每秒写入数万到数十万条消息是很轻松的。
零拷贝
Kafka对消息读取时,首先尝试从OS的pageCache中读取,读取成功则将消息通过页缓存直接发送到网络的Socket上。该过程利用了Linux平台上的sendfile系统调用实现,该技术的核心原理便是零拷贝(Zero Copy)。
零拷贝的原理示意图如下:
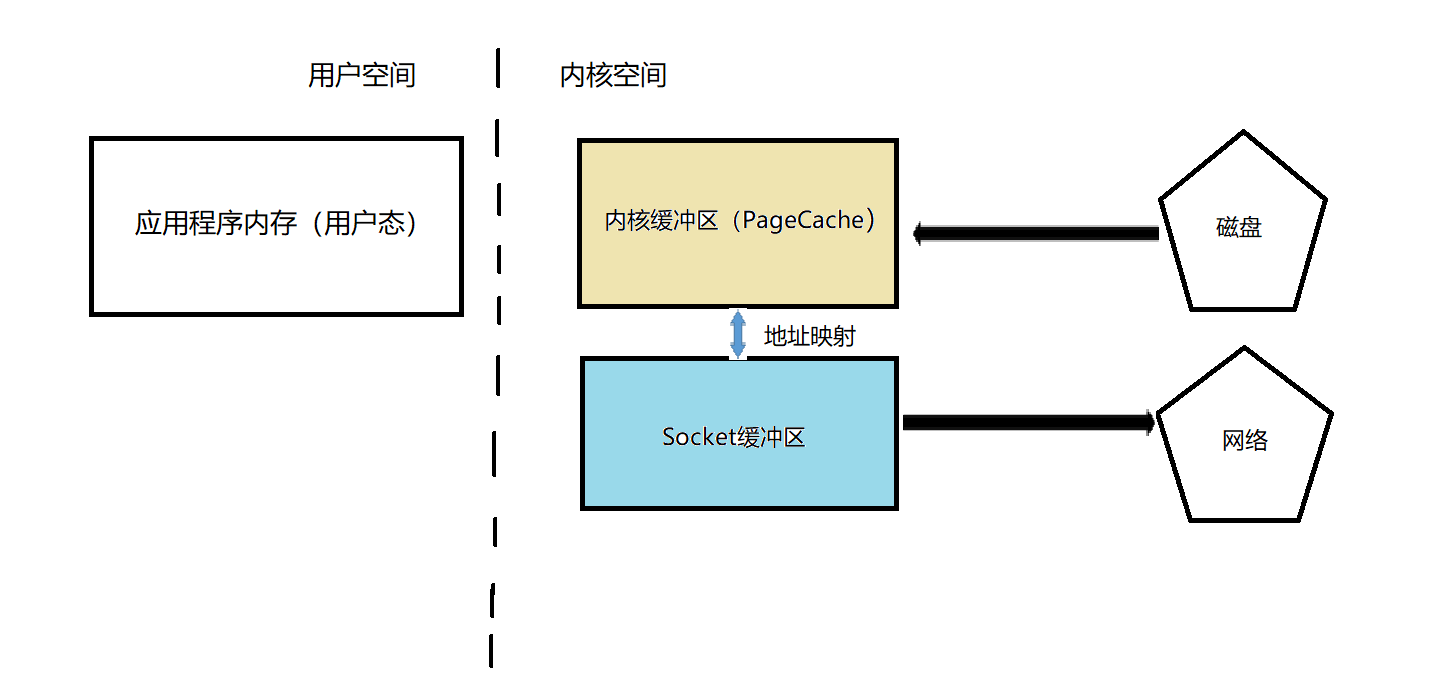
详解零拷贝
接下来对该图做一个较为详细的讲解:
传统Linux操作系统在进行I/O操作时是通过数据的复制(或者说拷贝)实现的,在零拷贝技术出现之前,一个I/O操作会对数据进行多次拷贝,该过程涉及到内核态与用户态的上下文切换,对于CPU的压力较大,无法做到高效率的进行数据的传输。
而零拷贝就是为改善该问题而存在的,当内核驱动程序通过I/O处理数据(如:从磁盘中读取文件)时,不需要进行上下文切换,即:无需将数据从内核缓冲区(PageCache)复制到应用程序内存(即用户态),而是直接在内核空间中从内核缓冲区拷贝到Socket缓冲区。节省了内核缓冲区与用户态应用程序内存之间的数据拷贝,
实际上,内核缓冲区与Socket缓冲区之间并没有真正的做数据拷贝操作,而是做了地址映射,当底层网卡驱动要读取数据并发送到网络的时候,看起来好像是读取了Socket缓冲区的数据,实际上是直接读取了内核缓冲区的数据,数据实际上只有一份,而这是利用了DMA(Direct Memeory Access,直接内存存储器访问技术)实现的,通过DMA进行I/O操作,不仅避免了内核缓冲区与用户缓冲区的数据拷贝,还减少了内核缓冲区与socket缓冲区间的数据拷贝,因此得名“零拷贝”。
Kafka的应用
Kafka消息消费机制使用的是Linux提供的sendfile系统调用实现的零拷贝技术,进一步说是通过Java的FileChannel.transferTo来实现的。
页缓存
Kafka大量使用了操作系统的页缓存,当读取消息时,由于大量的消息保存在页缓存中,因此读取消息能够直接命中缓存而不必穿透到底层的物理磁盘中获取消息,这极大的提升了消息读取的吞吐量。
在经过良好的系统调优的Kafka集群中,对于存在较明显负载的Broker机器而言,对物理磁盘的读操作也是很少的,这正是因为消息读取操作很大程度上是直接命中了页缓存而未到达物理磁盘。
小结
Kafka之所以能够表现出高吞吐、低延时的良好性能,主要依托本文提到的要点进行了设计:
- 大量地使用OS的页缓存进行操作,减少I/O性能消耗
- Kafka本身不进行物理I/O操作,而是利用了OS进行I/O操作
- 消息写入采用了追加写入的方式,避免了对磁盘的随机读写,从而极大的提高了写入的效率
- 采用“零拷贝”技术,极大的提升了网络传输效率。
