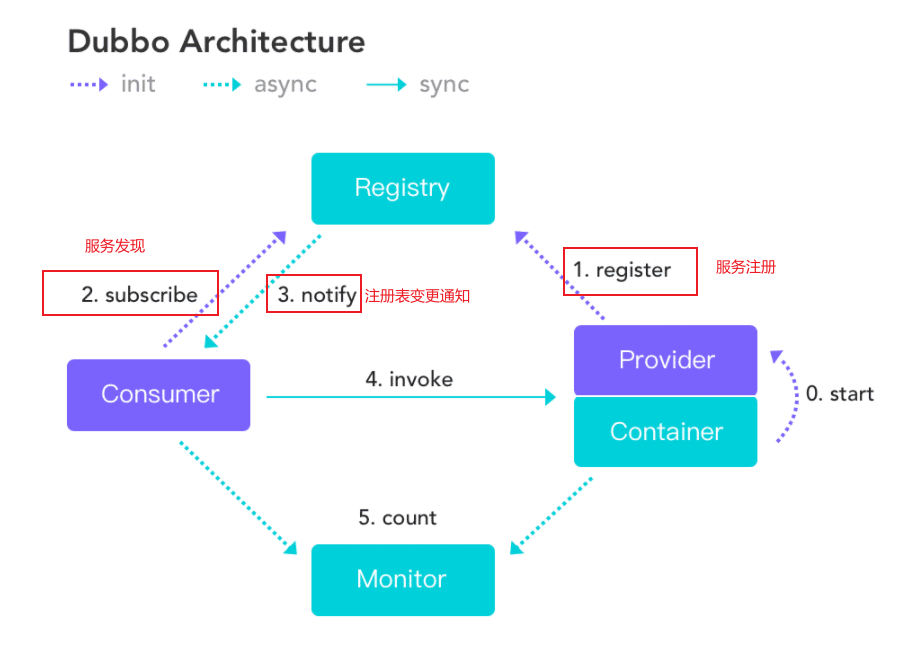
Ringbuffer(环形缓冲区/环形数组)是Disruptor的核心底层数据结构。
它不同于传统的阻塞队列(如:ArrayBlockingQueue)是从某一端入队,另外一端出队,而是一种收尾相连的环形结构。
之所以叫它 buffer,我想大概是因为这个环形队列是作为不同线程(or上下文)之间传递数据媒介,类似于一个缓冲区。
RingBuffer拥有一个序号,指向数组中下一个可用的元素,需要注意的是Disruptor中的RingBuffer没有头尾指针,而只通过序号(sequence)就实现了生产者与消费者之间的进度协调。
RingBuffer可以一直填充吗?
假如不断地填充RingBuffer,那么必然会发生sequence一直增加,直到绕过环,覆盖原有的内容。
Disruptor是通过barrier实现了是否要覆盖原有内容的判断,这部分内容后面会说到。
如何定位RingBuffer中的元素呢?
正如我们在前面所说,RingBuffer本质上是个数组,那么必然可以通过数组的偏移量offset或者说index,定位到具体的元素。
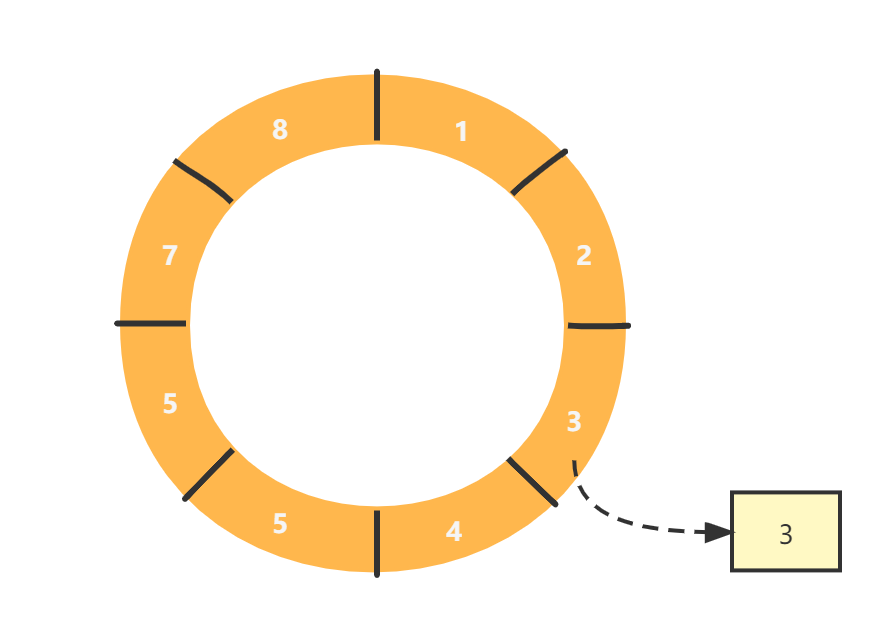
在实际的开发中,我们常通过取模运算来获取元素在数组中的偏移量。也就是 序号 % 长度 == 索引
假设有8个元素,那么元素序号为13的元素就位于:
13 % 8 = 5
对于Disruptor而言,它强制要求数组的size初始化为 2的N次方,如 1024 * 1024。
设置为2的N次方有这样的好处:可以通过位运算更快速定位到元素位置。公式为:
seq & (ringBufferSize - 1) == index
在Disruptor中, ringBufferSize-1 成为mask,即掩码。
RingBuffer中的数据是如何预热的?
RingBuffer通过预分配对象机制来降低GC的影响。在实际运行过程中,业务从RingBuffer中获取对应sequence位置的对象引用,对该引用指向的对象属性赋值,通过覆盖写方式而不是直接覆盖整个对象的方式,保证了对象引用在整个disruptor存活的周期内都存在,保证GCRoot始终存在,因此能够大幅降低GC的影响。
这也是Disruptor高性能保证的策略之一,由于Disruptor主要使用场景之一就是低延迟环境,因此必须减少运行时内存分配,从而减少垃圾回收导致的系统停顿(STW)。
这种预加载机制在其他的中间件也有使用,如RocketMQ的commitLog也是在broker启动时就创建固定1G的文件,便于启动完成便可进行写入而不需要进行运行期创建。
Disruptor的RingBuffer数据预热具体的实现,查看Disruptor源码:
Disruptor初始化过程中会初始化RingBuffer:
1 2 3
| RingBuffer( EventFactory<E> eventFactory,Sequencer sequencer){ super(eventFactory, sequencer); }
|
RingBuffer是RingBufferFields子类:
1
| public final class RingBuffer<E> extends RingBufferFields<E> implements Cursored, EventSequencer<E>, EventSink<E>
|
初始化RingBuffer时会先调用父类构造:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
| RingBufferFields(EventFactory<E> eventFactory, Sequencer sequencer) { this.sequencer = sequencer; this.bufferSize = sequencer.getBufferSize(); if (bufferSize < 1) { throw new IllegalArgumentException("bufferSize must not be less than 1"); } if (Integer.bitCount(bufferSize) != 1) { throw new IllegalArgumentException("bufferSize must be a power of 2"); } // 用于计算index的掩码,公式:seq & (ringBufferSize - 1) == index this.indexMask = bufferSize - 1; // 初始化RingBuffer数组 this.entries = new Object[sequencer.getBufferSize() + 2 * BUFFER_PAD]; // 预填充RingBuffer数组 fill(eventFactory); }
|
接着调用fill方法预填充数组,实现逻辑就是为数组的每个index填充一个对象实例。
1 2 3 4 5
| private void fill(EventFactory<E> eventFactory){ for (int i = 0; i < bufferSize; i++){ entries[BUFFER_PAD + i] = eventFactory.newInstance(); } }
|
填充操作通过用户定义的eventFactory实现,该工厂一般写法为:
1 2 3 4 5 6 7 8
| public class OrderEventFactory implements EventFactory<OrderEvent> { @Override public OrderEvent newInstance() { // new 一个空的orderEvent对象即可 // 就是为了返回空的event对象 return new OrderEvent(); } }
|
版权声明:
原创不易,洗文可耻。除非注明,本博文章均为原创,转载请以链接形式标明本文地址。