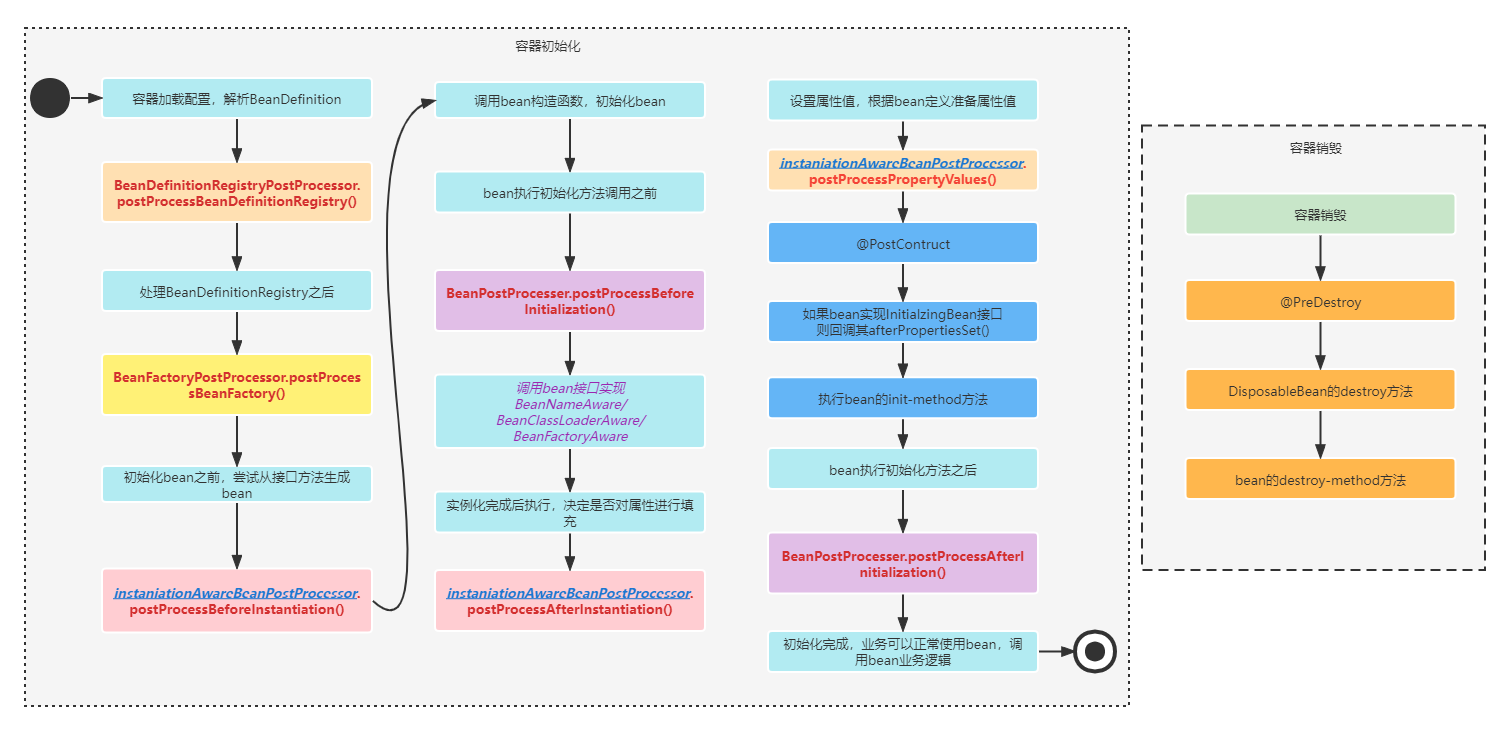
Disruptor高性能之道-缓存行填充
Disruptor高性能的另一个实现机制为 “缓存行填充”,它解决了CPU访问内存变量的“伪共享”问题。
什么是伪共享?
在解释什么是伪共享之前,先了解下数据在缓存中是如何存储的。
我们都知道,计算机为了解决CPU与主存之间速度差的问题,引入了多级缓存机制。
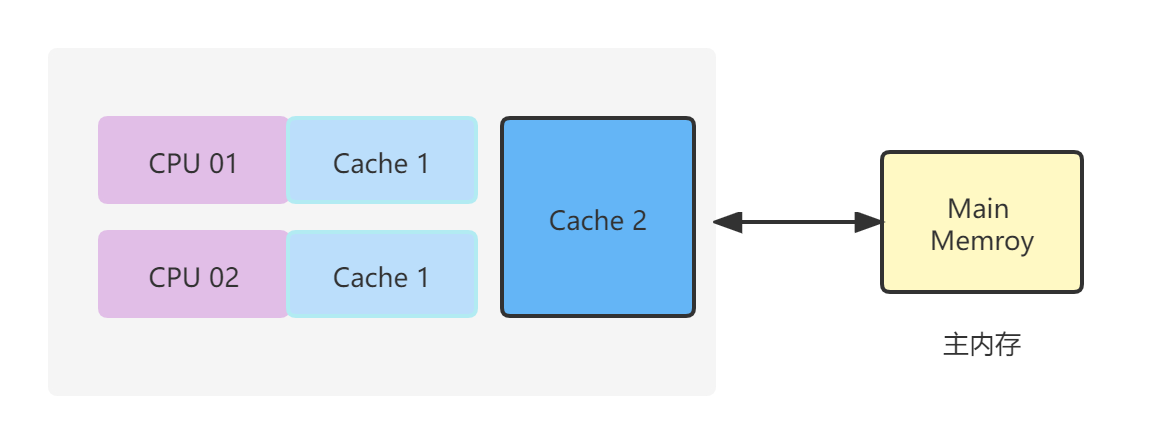
事实上,数据在CPU缓存(多级cache)中并非是单独存储的,而是按行存储的。其中每一行成为一个缓存行。
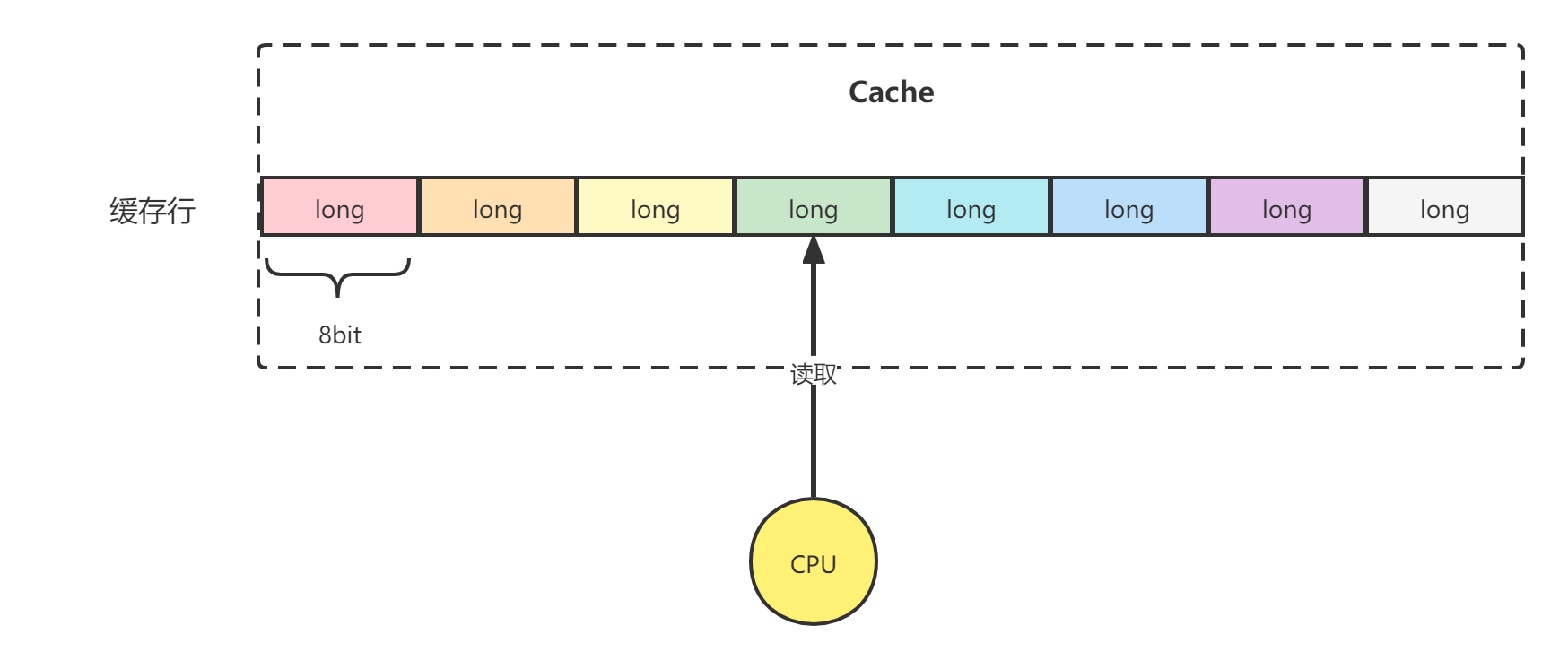
缓存行是CPU的Cache与主内存进行数据交换的基本单位,每个缓存行的大小一般为2的N次方字节。(在32位计算机中为32字节,64位计算机中为64字节。)可以想到,如果计算机为128位,则缓存行大小就是128字节。
在Java中,一个long型变量为8字节,也就是说在64位计算机中,每行可存放8个long型变量。
当CPU访问某个变量的时,如果CPU Cache中存在该变量,则直接获取。若不存在则去主内存获取该变量。由于缓存行机制的存在,因此会将该变量所在内存区域为一个缓存行大小的内存复制到CPU Cache中。
此时有可能会在一行缓存行中加载多个变量,如图中不同的颜色对应不同的long型变量。
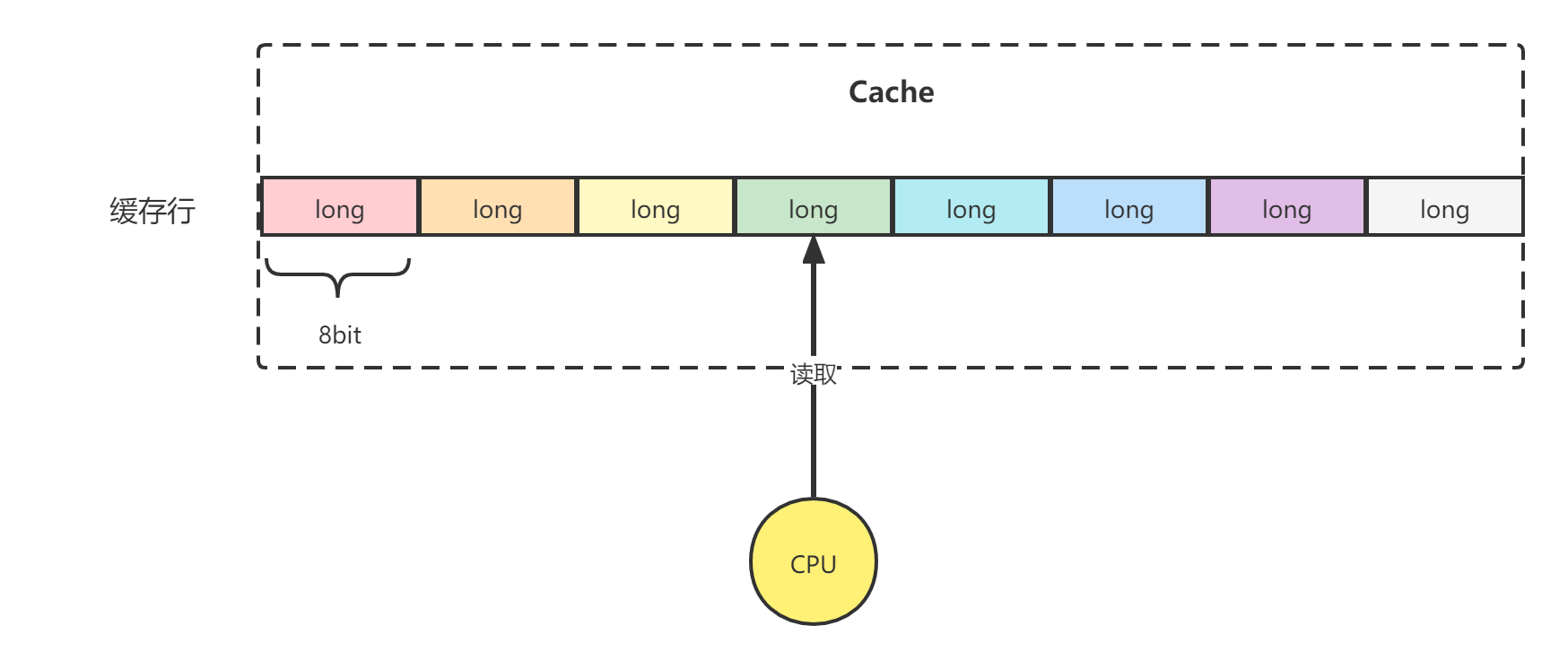
试想,如果多个内核的线程都操作了同一缓存行的数据,如图所示。CPU1读取并修改了缓存行中的变量D,了解volatile的同学都知道,当CPU Cache中的变量发生变更,会通过缓存一致性协议通知其他CPU失效当前缓存行,重新从主内存中加载当前行的值。
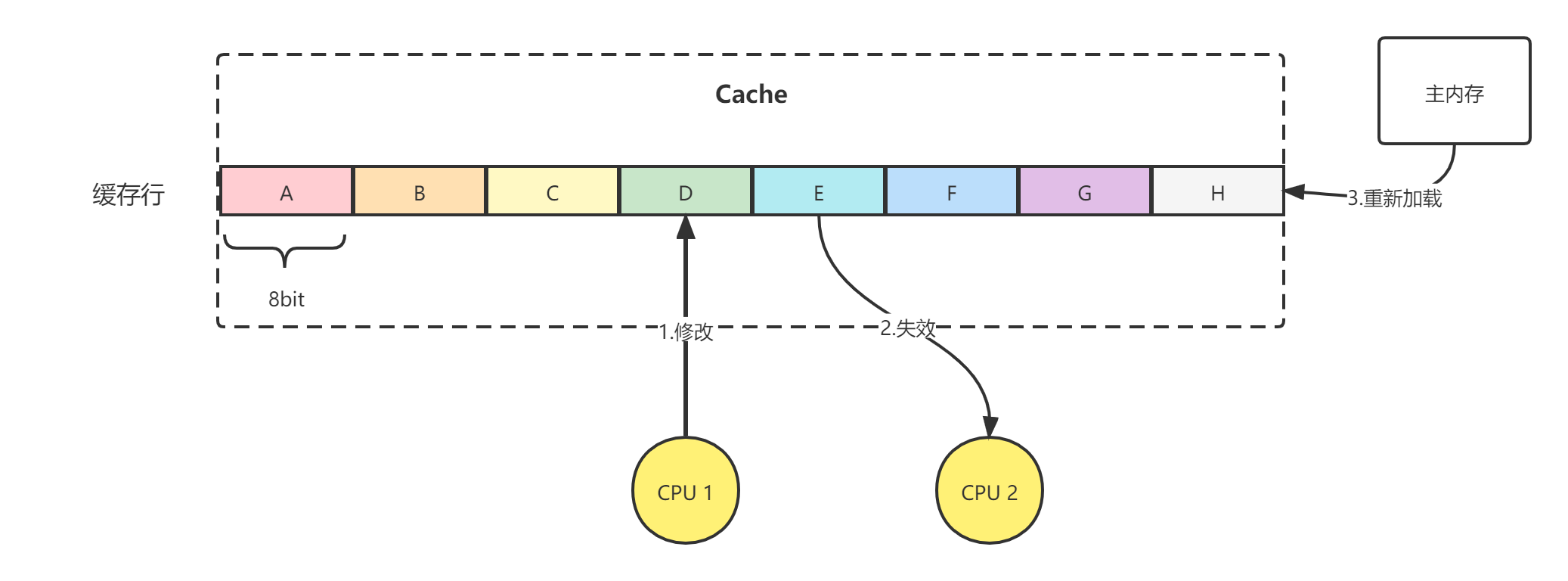
图中,CPU1修改了缓存行中的变量D,CPU2也在读取该缓存行的值。根据缓存一致性协议,CPU2中的缓存行会失效,因为它操作的缓存行中的变量D的值已经不是最新值了。
这是因为CPU是以缓存行为单位进行数据的读写操作的。
这就是伪共享。
为什么是“伪”共享呢?
看起来CPU1 与 CPU2 共享了同一个缓存行,但是由于CPU以缓存行为单位进行读写操作,无论CPU1 与 CPU2中的任何一位修改了缓存行中的值,都需要通知其他CPU对失效该缓存行。也就是说当线程对缓存进行了写操作,则当前线程所在内核就需要失效其他内核的缓存行,并重新加载主内存。
这是一种缓存未命中的情况,当发生这样的情况,缓存本身的意义就被削弱了,因为CPU始终需要从主内存加载数据,而根本命中不了CPU Cache中的缓存。
所谓的“伪”共享,就可以理解成是一种 “错误”的共享,这种共享如果不发生,则多核CPU操作缓存行互不影响,每个核心都只关心自己操作的变量,而不会因为读写自己关心的变量而影响到其他CPU对变量的读写。
Disruptor是如何进行缓存行填充的?
Disruptor解决伪共享的方式为:使用缓存行填充。
上文我们提到,由于多核CPU同时读写统一缓存行中的数据,导致了CPU Cache命中失败的伪共享问题。
那么只需要避免多核CPU同时操作统一缓存行,不就可以解决这个问题了么?
事实上,Disruptor正是这么做的。
Disruptor为Sequence中的value(volatile修饰)进行了缓存行填充,保证每个sequence只在一个缓存行中存在,避免了其他的变量对sequence的干扰。
其他的缓存行填充机制
JDK1.8 提供了注解 @Contended 用于解决伪共享问题,需要注意的是,如果业务代码需要使用该注解,要添加JVM参数
-XX:-RestrictContended。
默认填充宽度为128,若需要自定义填充宽度,则设置
-XX:ContendedPaddingWidth
具体的使用方式为:
|
|
参考资料
- 《Java并发编程之美》
- 并发编程网:剖析Disruptor:为什么会这么快?(二)神奇的缓存行填充
版权声明:
原创不易,洗文可耻。除非注明,本博文章均为原创,转载请以链接形式标明本文地址。